在数字化时代,文档的电子化日益普及,但随之而来的OCR(Optical Character Recognition,光学字符识别)技术在PDF文件中的应用也变得越来越重要。OCR技术能够将扫描纸质文档或图片上的文字转换为可编辑的文本,极大地提高了文档处理的效率和准确性。本文将详细介绍PDF OCR技术的工作原理、应用领域以及操作步骤,帮助您更好地利用这一工具提升工作效率。
OCR是一种通过计算机算法识别印刷或手写文本的技术。它通过分析图像中的像素信息,将其转换为对应的文字编码。随着技术的发展,OCR的准确性和速度都有了显著提升,使得纸质文档的数字化处理变得更加方便快捷。
高效性:OCR技术能够快速将PDF图片中的文字识别并转换为文本格式,大大缩短了文档处理的时间。
准确性:随着算法的不断优化,OCR技术的识别准确率不断提高,能够处理各种复杂背景下的文字识别。
灵活性:OCR技术不仅能够处理标准印刷文本,还能够识别手写体文字和一些特殊的排版格式。
跨平台应用:OCR技术不依赖于特定的操作系统或软件,可以在不同的平台和设备上运行。
档案数字化:将纸质档案扫描成电子版,便于存储和管理。
票据识别:自动识别和提取发票、车票等票据上的关键信息。
手写笔记转写:将会议记录、学习笔记等手写内容转换为电子文本。
图像文档分析:对包含文字的图片进行分析和信息抽取。
以枣知网在线工具为例,以下是使用OCR技术的详细步骤:
步骤一:打开枣知网,点击导航栏中的【PDF转换】,然后选择【PDF OCR】。
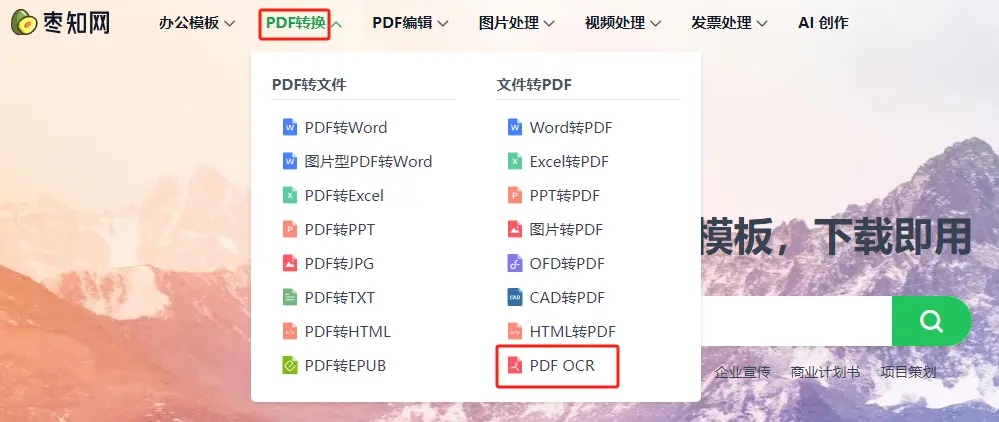
步骤二:点击或拖动上传您要进行文字识别的 PDF 文件。

步骤三: 文件上传成功后系统会自动对文件进行文字识别,您只需等待即可。
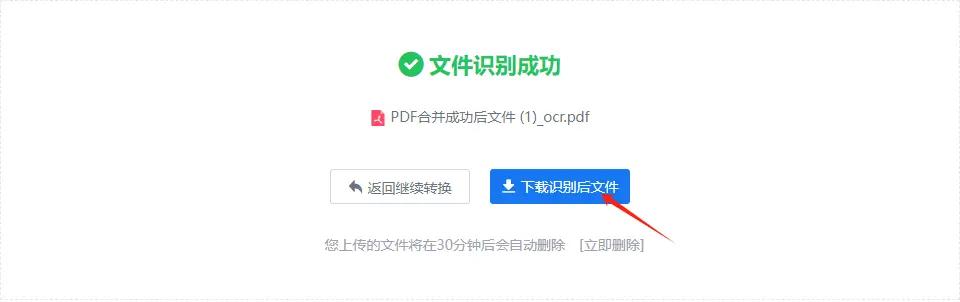
步骤四:文件识别成功后,您即可下载识别后的 PDF 文件。
1.图像质量:确保扫描的图像清晰,文字可辨,以提高OCR的识别准确率。
2.文件大小:对于过大的文件,OCR处理可能需要较长时间,您可以考虑将文件分割成多个小文件进行处理。
3.后处理:OCR技术可能无法完全识别所有特殊字符和排版,您可能需要进行一些手动校对的后期处理。
通过以上介绍,我们可以看到PDF OCR技术在文档数字化处理中的重要性和实用性。掌握这项技术,不仅能够提高工作效率,还能够帮助您更好地管理和利用电子文档资源。


